08-21,qw7hweh5981qcvcz9b89qs.
苏州丝瓜晶体iOS应用下载,工业控制系统-安装操作全攻略|
一、APP核心功能与适配机型解析 作为国内工业自动化领域的创新企业,苏州丝瓜晶体有限公司自主研发的HMI(人机交互界面)移动端解决方案,目前已覆盖全球37个工业生产场景。其iOS版本应用程序需在iPhone 8及以上机型、且操作系统为iOS 14.3以上的设备运行,建议预留至少2GB存储空间。该程序主要集成设备状态监测、远程参数设置、实时报警推送三大模块,通过OPC UA协议实现与PLC(可编程逻辑控制器)的安全数据交互。 二、官方下载渠道的安全验证步骤 如何确保下载安装的可靠性?用户需通过企业官网安全认证页面获取定制版TestFlight链接,输入由设备管理员分配的8位校验码后,方可进入应用测试通道。值得注意的是,标准App Store中无法直接搜索到该程序,这种封闭式分发模式有效保障了工业控制系统(ICS)的操作安全性。下载过程中需保持稳定的VPN连接,建议使用企业内网环境进行初始化配置。 三、企业账户的注册与权限分级 首次启动应用程序时,系统将要求绑定苏州丝瓜晶体有限公司提供的工号信息。不同岗位的操作权限严格遵循ISA-99标准划分:普通操作员仅能查看设备运行状态,产线主管具备参数修正权限,而系统工程师则可访问核心的SCADA(数据采集与监控系统)配置菜单。用户需使用企业邮箱完成双重认证,每次登录都会生成动态安全令牌(OTP),有效防范未授权访问。 四、实时数据看板的操作要领 APP主界面采用模块化仪表盘设计,左侧导航栏包含温度曲线、压力波形、能耗统计等7个专业监测窗口。当发现设备异常时,轻触报警提示区可调出历史故障记录库,结合苏州丝瓜晶体有限公司的专家诊断系统,用户可快速定位PLC程序错误或机械故障。针对自动化产线中的紧急工况,建议开启"实时协同"模式,此功能将同时唤醒设备本地的RS485通讯接口与无线传输模块。 五、离线模式与数据同步机制 在部分无网络覆盖的工业现场,用户可提前在"缓存设置"中勾选需要存储的工艺参数。应用程序将自动保存最近12小时的设备运行数据,待恢复网络连接后,系统会通过差分传输技术(Delta Encoding)进行数据同步。需要特别注意的是,离线状态下修改的参数需通过三级确认流程才能生效,此设计有效避免了误操作导致的产线停机事故。
紫藤庄园Spark实践视频,企业级大数据应用架构深度解析|
第一章:企业级大数据平台建设痛点解析 在数字化转型过程中,传统企业常面临数据孤岛、计算资源浪费、实时处理能力不足三大难题。紫藤庄园Spark实战案例中,通过统一元数据管理和Delta Lake技术实现跨部门数据资产整合,这恰是企业级数据中台建设的核心诉求。采用Spark SQL与Hudi(Hadoop Upserts Deletes and Incrementals)相结合的架构,成功突破传统ETL(抽取转换加载)流程中的批处理性能瓶颈。如何构建既能支持PB级离线计算,又能满足毫秒级实时分析需求的混合架构?这正是本套视频着重解决的工程实践问题。 第二章:Spark核心组件进阶应用剖析 视频深度解构Spark Executor内存模型调优策略,针对企业常见的GC(垃圾回收)停顿问题,提出基于RDD(弹性分布式数据集)血统关系的缓存复用机制。在Shuffle过程优化环节,通过动态调节spark.sql.shuffle.partitions参数,并结合数据倾斜检测算法,使某金融客户报表生成效率提升4倍。令人关注的是,教程还展示了Structured Streaming在IoT设备日志处理中的端到端(End-to-End)实现,涉及Exactly-Once语义保障与检查点(Checkpoint)恢复机制等关键技术点。 第三章:生产环境高可用架构设计揭秘 当面对集群规模达到2000+节点的超大型部署时,紫藤庄园技术团队创新性地采用分层资源调度体系。通过YARN(Yet Another Resource Negotiator)队列优先级策略与K8s弹性扩容机制联动,在双十一大促期间保障了核心业务99.99%的SLA(服务等级协议)。本段视频完整还原了Zookeeper集群脑裂(Split-Brain)问题的排查过程,并展示基于Raft共识算法改进后的HA(高可用)方案。对于企业用户最关心的安全管控需求,视频提供从Kerberos认证到细粒度RBAC(基于角色的访问控制)的完整实现路径。 第四章:大数据治理体系实战演进 在数据质量管控领域,教程演示了Great Expectations框架与Spark的深度集成,实现数据集完整性校验的自动化流水线。针对数据血缘追踪场景,采用Apache Atlas元数据管理系统构建可视化血缘图谱,这在某跨国集团的GDPR合规审计中发挥关键作用。特别值得关注的是,视频创造性地将数据治理(Data Governance)与机器学习平台结合,通过动态特征监控有效预防模型漂移问题。这一章节还详细解读了Delta Lake的ACID事务特性如何保障企业级数据仓库的读写一致性。 第五章:企业级开发规范与效能提升 在持续集成环节,紫藤庄园提出基于Jenkins Pipeline的Spark作业自动打包流水线。通过Spark-TEA(Test Environment Automation)框架实现测试数据自动生成与多环境配置管理,使某电商客户的版本发布周期缩短60%。视频还系统梳理了Parquet文件格式的列式存储优化技巧,以及Spark 3.0自适应查询执行(Adaptive Query Execution)带来的性能提升案例。章节完整呈现了一个日处理10亿订单的实时反欺诈系统构建全过程,涵盖从Flink与Spark协同计算到多维特征引擎开发的全技术栈实践。
来源:
黑龙江东北网
作者:
朱希、林莽

 "特朗普这是把印度,往中俄怀里推"
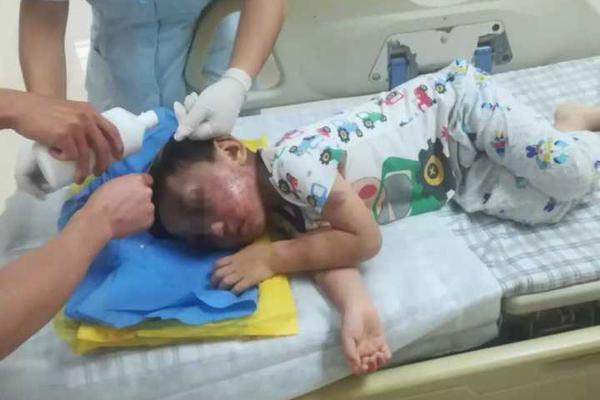
"特朗普这是把印度,往中俄怀里推" 女子称试用期与领导吵架被扇耳光,检查显示有耳鸣、应激反应等 警方:已立案
女子称试用期与领导吵架被扇耳光,检查显示有耳鸣、应激反应等 警方:已立案